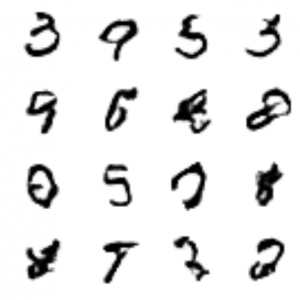NBTABY .. Nothing but today, Anything but yesterday.
What is GAN?-Counterfeiter and Policeman 🚓
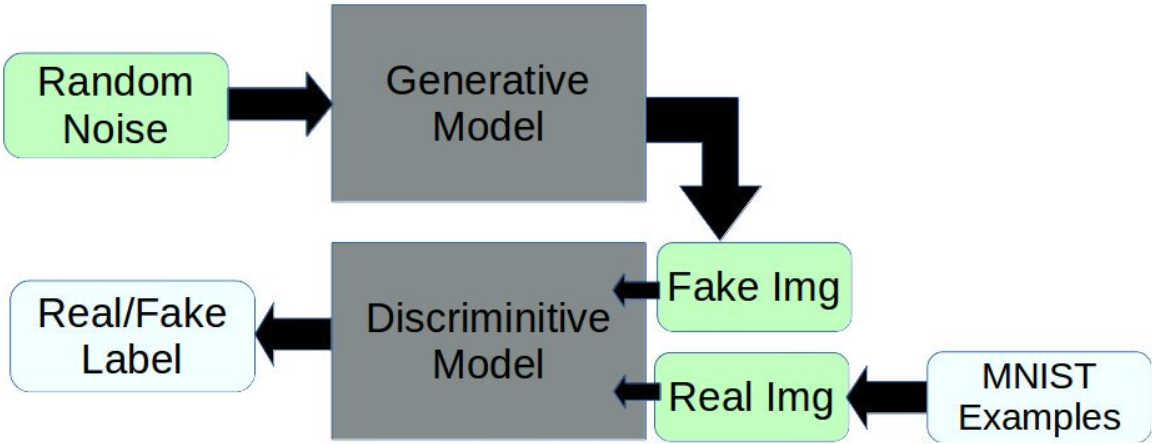
The GAN (Generative Adversarial Nets) model is a model that lets you learn how to create results by competing two opposing neural networks. The dictionary meaning of the word “adversarial” has the meaning of confrontation and opposition. In order to confront, you have to have an opponent anyway, so you can intuitively know that GAN is largely divided into two parts.
By Tim O’Shea, O’Shea Research.
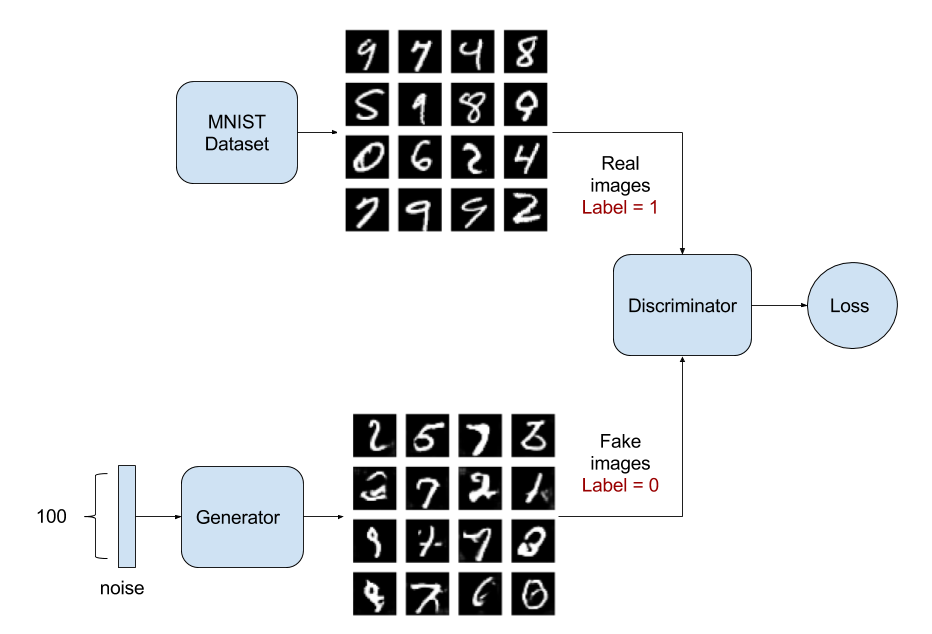
Some of the generative work done in the past year or two using generative adversarial networks (GANs) has been pretty exciting and demonstrated some very impressive results. The general idea is that you train two models, one (G) to generate some sort of output example given random noise as input, and one (A) to discern generated model examples from real examples. Then, by training A to be an effective discriminator, we can stack G and A to form our GAN, freeze the weights in the adversarial part of the network, and train the generative network weights to push random noisy inputs towards the “real” example class output of the adversarial half.
1.0 Counterfeiters are becoming more intelligent by competing.
According to the analogy presented by Ian Goodfellow, who proposed the GAN model, the counterfeiter (producer neural network) and the policeman (constituent neural network) oppose each other, and the police try to discriminate, and the counterfeiter is counterfeit. It is to learn how to make high-quality counterfeit bills that are difficult to distinguish from the real through the relationship that advances the method.
importosimportsysimporttensorflowastfimportmatplotlib.pyplotaspltimportnumpyasnp# Set 'root-dir' and 'working-dir' - for Atom Environment, Script-Run
DIRS=os.path.dirname(__file__).partition("deep_MLDL")ROOT=DIRS[0]+DIRS[1]sys.path.append(ROOT)fromos.pathimportdirname,joinWORK_DIR=join(ROOT,'_ static','MNIST_data','')fromtensorflow.examples.tutorials.mnistimportinput_datamnist=input_data.read_data_sets(WORK_DIR,one_hot=True)# Hyper- Parameter
learning_rate=2e-4training_epoches=100batch_size=100n_hidden=256n_input=28*28# 784 pix. for 1 letter
n_noise=128# placeholder
X=tf.placeholder(tf.float32,[None,n_input])Z=tf.placeholder(tf.float32,[None,n_noise])G_W1=tf.Variable(tf.random_normal([n_noise,n_hidden],stddev=0.01))G_b1=tf.Variable(tf.zeros([n_hidden]))G_W2=tf.Variable(tf.random_normal([n_hidden,n_input],stddev=0.01))G_b2=tf.Variable(tf.zeros([n_input]))D_W1=tf.Variable(tf.random_normal([n_input,n_hidden],stddev=0.01))D_b1=tf.Variable(tf.zeros([n_hidden]))D_W2=tf.Variable(tf.random_normal([n_hidden,1],stddev=0.01))D_b2=tf.Variable(tf.zeros([1]))